スプレッドシートの空白行をクエリ関数(QUERY)を使って詰める方法

スプレッドシートで空白行を削除する方法には、フィルタ機能を使った一括削除のほか、クエリ関数(QUERY)を活用しても空白行を除外することが可能です。
クエリ関数(QUERY)は、元のデータをそのまま保持しながら、空白行を除外した状態で別シートに表示できます。
そのため、データが更新された際にも自動で反映され、手作業での整理が不要になります。
この記事では、クエリ関数を使ってスプレッドシートの空白行を除外する方法 をご紹介します。

完成イメージ
クエリ関数適用前
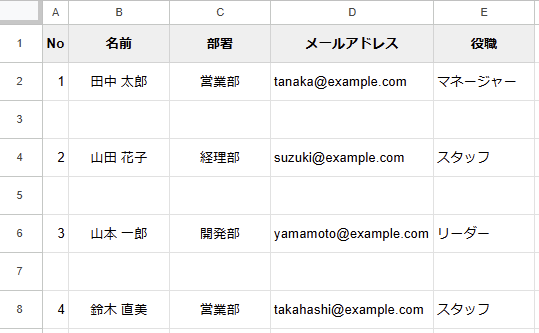
クエリ関数適用後

- 元データを残したまま、別のシートで空白行を除外して表示
- 元データが変更されても自動的に更新されるため、手作業での調整が不要
クエリ関数を使った空白行の除外方法
クエリ関数は、スプレッドシートのデータを条件に応じて抽出し、整理するための便利な機能です。
空白行を除外するには、WHERE 句を使って、特定の列にデータがある行のみを取得します。
空白行が含まれている元データを確認します。
例として、シート名を「データ」にします。
(シート名は必要に応じて変更)
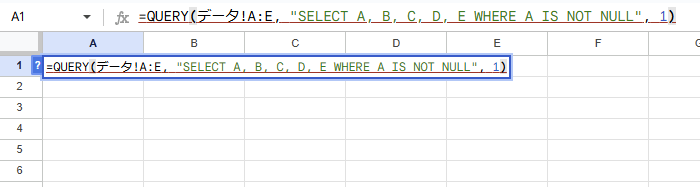
新しいシートのセルにクエリ関数を入力します。
例えば、A列が空でない行を抽出する場合:
=QUERY(データ!A:E, "SELECT A, B, C, D, E WHERE A IS NOT NULL", 1)数式の説明
データ!A:E→ 別シート「データ」のA列からE列までのデータ範囲を対象にします。SELECT A, B, C, D, E→ A列からE列のデータを取得します。WHERE A IS NOT NULL→ A列が空でない行のみを取得します。1→ 1行目を見出しとして扱います。
(参考)A列だけでなく、B列やC列も空でないことをチェックしたい場合:
=QUERY(データ!A:E, "SELECT A, B, C, D, E WHERE A IS NOT NULL OR B IS NOT NULL OR C IS NOT NULL", 1)数式の説明
OR を使って、いずれかの列が空でない行のみを取得します。
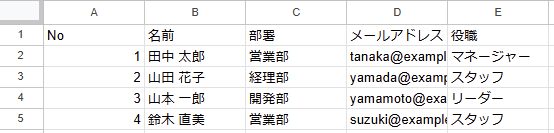
空白行を除外したデータが表示されます。
列幅や書式設定は反映されないため、必要に応じて元のデータとフォーマットを合わせます。
また、元のデータを変更するとクエリ関数の結果も更新されます。
そのため、結果を固定したい場合は「コピー → 値として貼り付け」を行います。
クエリ関数の応用
クエリ関数では複数の条件を設定してデータを抽出することができます。
例えば、「A列が空でなく、かつC列の値が ‘営業部’ の行のみ取得」
=QUERY(データ!A:E, "SELECT A, B, C, D, E WHERE A IS NOT NULL AND C = '営業部'", 1)表示結果
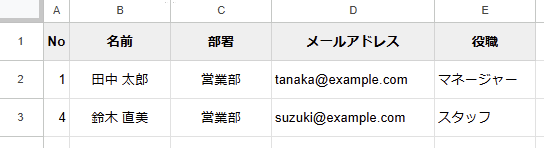
空白行を除外しつつ、”営業部”のみのデータを抽出できます。
クエリ関数で空白行を除外した後、部署を昇順に並び替え
=QUERY(データ!A:E, "SELECT A, B, C, D, E WHERE A IS NOT NULL ORDER BY C ASC", 1)ORDER BY C ASC→ C列のデータを昇順で表示
表示結果

部署ごとにデータが並び替えられた状態で表示されます。
クエリ関数のメリット・デメリット
| メリット | デメリット |
|---|---|
| データをすぐに整理できる データが変更されても動的に更新される 複数の条件を組み合わせて、柔軟にデータ整理可 | 関数の構文がやや複雑 データ範囲が大きいと、処理が遅くなる 元のデータを直接変更するわけではない |
- データをすぐに整理できる
-
クエリ関数を使えば、元のデータを変更せずに必要なデータだけを抽出し、空白行を除去した状態で表示できます。
フィルタ機能のように手動でデータを整理する必要がなく、効率的にデータを扱えます。
- データが変更されても動的に更新される
-
元のデータに新しい行を追加したり、既存のデータを修正した場合でも、自動的に最新の状態に反映されます。
- 複数の条件を組み合わせて、柔軟にデータを整理可
-
WHEREやORDER BYを活用することで、空白行を除外するだけでなく、特定の条件に合致するデータのみを表示したり、並び替えを行うことができます。
- 関数の構文がやや複雑
-
クエリ関数の構文にはデータベースの検索や抽出に使われる形式が含まれているため、スプレッドシートの基本的な関数しか使ったことがない場合は、理解に時間がかかることがあります。
- データ範囲が大きいと、処理が遅くなる
-
クエリ関数はリアルタイムでデータを処理するため、大量のデータを扱うと処理速度が遅くなる可能性があります。
- 元のデータを直接変更するわけではない
-
クエリ関数の結果は元データを参照しているため、固定したデータとして保持したい場合は「値として貼り付け」を行う必要があります。
まとめ
クエリ関数を使えば、スプレッドシートの空白行を自動的に除外し、データを整理することができます。
手作業で削除する必要がなく、データの変更にも動的に対応できるため、業務の効率化につながります。
一方で、クエリ関数の構文に慣れるまで時間がかかることや、大量のデータを処理する際に動作が遅くなることがあります。
そのため、
- 一時的に手作業で整理するなら「フィルタ機能」
- データを残したまま整理するなら「クエリ関数」
- 大量データを整理&自動化するなら「GAS」
など、用途に応じて使い分けると効率的です。



弊社では、Google Apps Script(GAS)を活用した業務効率化のサポートを提供しております。
GASのカスタマイズやエラー対応にお困りの際は、ぜひお気軽にご相談ください。
また、ITツールの導入支援やIT導入補助金の申請サポートも行っております。
貴方の業務改善を全力でサポートいたします。
関連記事
-
 Googleフォーム受付停止・再開を一括管理|スプレッドシート×GAS 有料テンプレート
Googleフォーム受付停止・再開を一括管理|スプレッドシート×GAS 有料テンプレート -
Googleフォーム回答受付を一括管理|GASでスプレッドシートに一覧表示
-
ファイル管理・外部連携テンプレート集|Googleドライブ × Webサービスを効率化【有料】
-
Gmail・カレンダー業務を効率化する有料テンプレート集|Googleスプレッドシート × GAS
-
スプレッドシート操作を効率化する有料カスタムメニュー&テンプレート集|Googleスプレッドシート × GAS【有料】
-
GASで作るカスタムメニュー(空白・改行)|選択範囲の行列削除やセル整形をカンタンに
-
GASで作る移動メニュー|最終セルジャンプ&シートタブ移動を一括操作
-
スプレッドシートの承認機能の使い方|Google Workspaceでできること








コメント